
|
|
Aktuell information för kursen SF1901 Sannolikhetsteori och statistik, 6hp, för CINEK2, period 2, ht 2015.
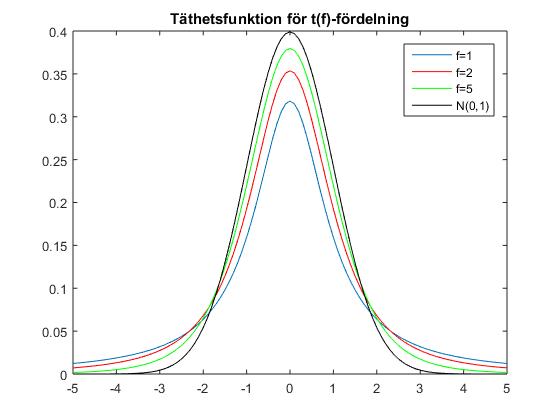
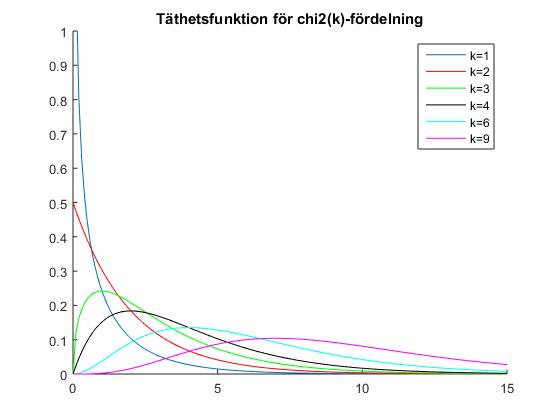
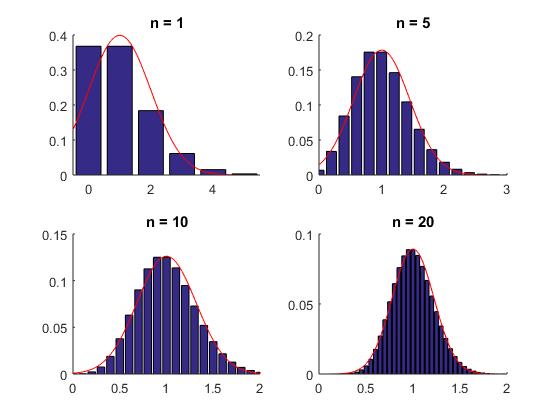
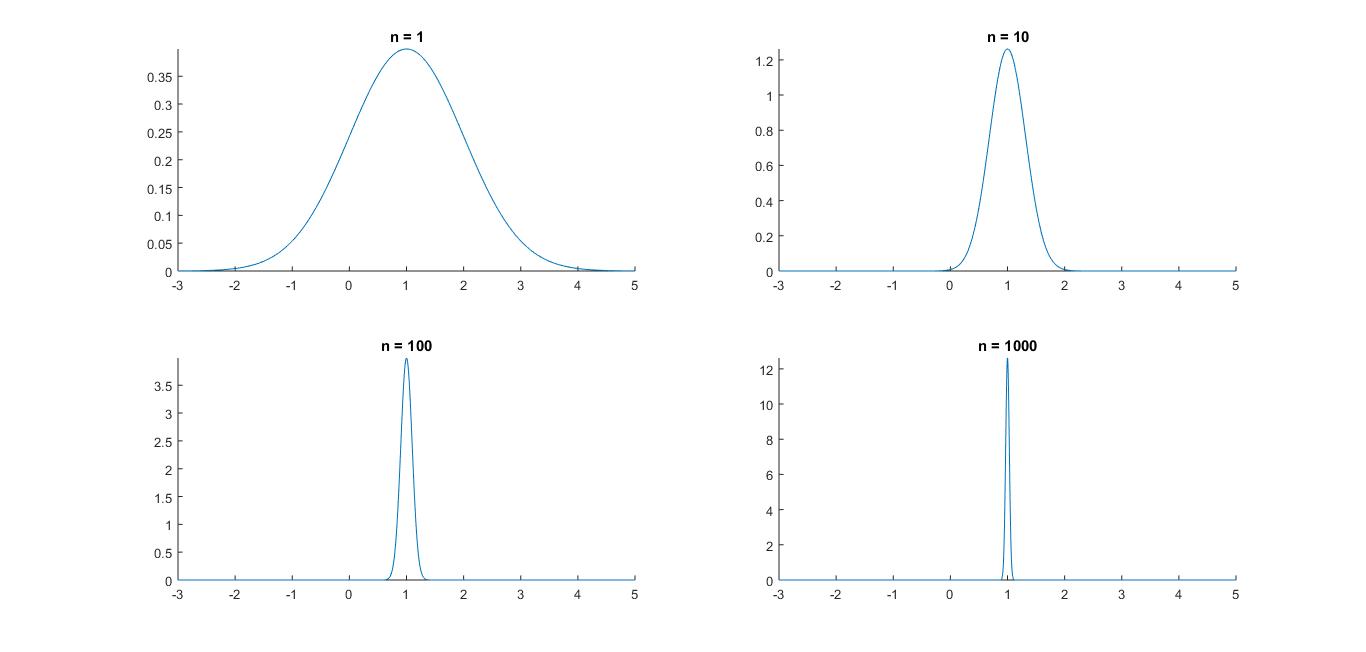
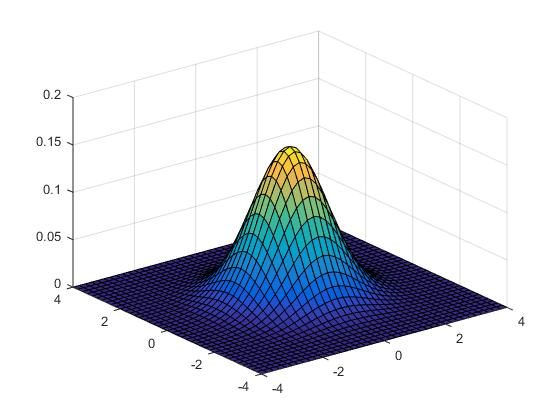
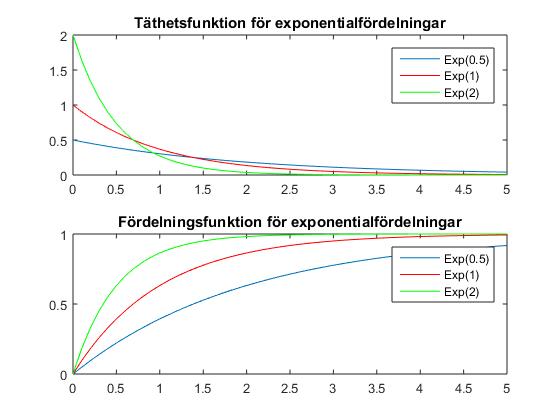
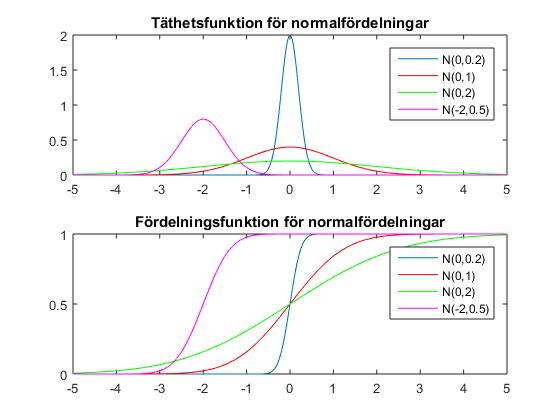
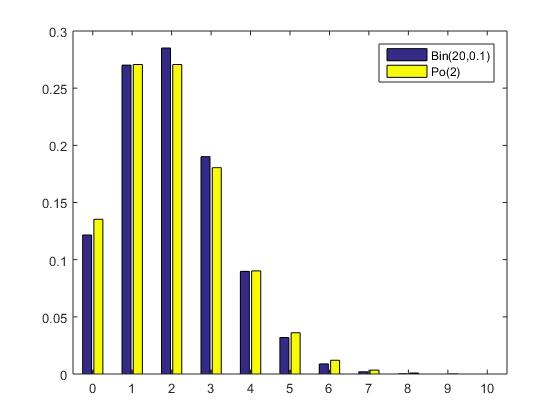
Här ges fortlöpande information om schemaändringar, vad som gåtts igenom på föreläsningar etc. KursutvärderingKontrollskrivningLösningsförslag till kontrollskrivningen som gick tisdag 24 november, kl 08.00-10.00 finns här (längst ned i dokumentet).FöreläsningsinformationFöreläsning 15 (151217)På föreläsning 15 går vi igenom tentamen från 17 augusti 2015.Föreläsning 14 (151215)På föreläsning 14 fortsatte vi med chi2-test och visade hur dessa kunde användas för att testa hypotesen att ett stickprov kommer från en given fördelning med okända parametrar. Vi fortsatte med homogenitetstest (test av om flera stickprov kommer från en och samma fördelning) och oberoendetest (test av om två egenskaper hos ett stickprov är oberoende). Vi hann inte med felfortplantning på föreläsningen, men detta tas upp i föreläsningsanteckningarna. Även regression lämnas till självstudier. För den (mycket) intresserade ges här en (ganska svår) genomgång av teoretisk statistik.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar (föreläsning 14) Jan Grandells och Timo Koskis föreläsningsanteckningar (föreläsning 15) Föreläsning 13 (151211)På föreläsning 13 diskuterade vi skillnaden mellan typ I-fel (att förkasta nollhypotesen trots att den är sann) och typ II-fel (att inte förkasta nollhypotesen trots att den är falsk). Storleken på typ I-felet i ett test kvantifieras av den givna felrisken alfa och vi introducerade styrkefunktionen för att kvantifiera typ II-fel. Vi illustrerade användning av styrkefunktionen med ett exempel om rattfylleri. Vi undersökte därefter hur normalapproximationen kan användas vid hypotesprövning. Vi avslutade med en introduktion till chi2-test och visade med ett exempel hur vi kan testa hypotesen att ett stickprov har en given fördelning med kända parametrar.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 12 (151208)Föreläsning 12 ägnades åt hypotesprövning, vilket innebär att med matematiska metoder avgöra om en uppställd hypotes stöds av de givna observationerna eller ej. Vi introducerade grundbegreppen nollhypotes, mothypotes, testvariabel, kritiskt område, signifikansnivå (felrisk) och p-värde samt illustrerade begreppen med två exempel, varav det andra finns här. Vi avslutade med att undersöka hur konfidensintervall kan utnyttjas för att pröva hypoteser och tog ett exempel där hypotesen gällde väntevärdet för ett normalfördelat stickprov.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 11 (151204)På föreläsning 11 fortsatte vi att studera konfidensintervall. Vi började med att undersöka två olika sätt att jämföra normalfördelade stickprov. Först studerade vi två oberoende stickprov från två olika normalfördelningar och bestämde ett konfidensintervall för skillnaden mellan de båda normalfördelningarnas väntevärden. Vi exemplifierade detta med ett medicinskt försök där vi ville avgöra om en medicin ger bättre effekt än placebo. Sedan studerade vi stickprov i par, vilket innebär att vi utför två olika mätningar på ett antal objekt, exempelvis kan vi mäta vikten hos ett antal individer före och efter de genomgår en viss diet. Vi tog fram konfidensintervall för den systematiska skillnaden mellan mätningarna genom att studera stickprovet av differenserna mellan de båda mätningarna. Avslutningsvis visade vi att, tack vare centrala gränsvärdessatsen, kan vi använda kvantiler för den standardiserade normalfördelningen för att bestämma konfidensintervall för stickprov som inte är normalfördelade (under förutsättning att stickproven är tillräckligt stora). Vi exemplifierade detta med en opinionsundersökning där konfidensintervall med konfidensgrad 95% har utseendet punktskattning±1.96*medelfel.Jag har lagt upp en ny version av föreläsning 11 eftersom jag hade gjort ett felaktigt påstående i den föregående versionen. I den nu borttagna versionen påstod jag att vi från konfidensintervallet för mu1-mu2 kunde dra slutsatsen att medicin A var bättre än placebo med 95% sannolikhet om konfidensintervallet inte innehöll noll. Det är sant att konfidensintervallet som vi tog fram för mu1-mu2 med 95% sannolikhet innehåller det sanna värdet på mu1-mu2, men vi kan däremot inte säga att mu1-mu2 med 95% sannolikhet ligger i konfidensintervallet eftersom mu1-mu2 har ett fixt värde. Antingen ligger mu1-mu2 i det intervall som vi har fått fram eller inte, det är inte en fråga om sannolikhet. Man kan jämföra med Buffons nålproblem (exempel 4.5 på sid 91) som ger en möjlighet att skatta pi experimentellt och därigenom få ett konfidensintervall för pi. Om man nu fått intervallet (3.1,3.2) eller kanske (3.2,3.5) är det ju inte så att pi ligger i det givna intervallet med sannolikheten 95%. Antingen ligger parametern i det konkreta intervallet eller så gör det inte det. Thomas Önskogs föreläsninganteckningar (OBS! Ny version 151207.) Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 10 (151201)Föreläsning 10 behandlade konfidensintervall, vilka kan användas för att ge ett mått på osäkerheten i en punktskattning. Vi tog fram en procedur för att bestämma konfidensintervall och tillämpade denna på tre olika typer av konfidensintervall för normalfördelade stickprov. Först undersökte vi konfidensintervall för väntevärdet av ett normalfördelat stickprov i fallet då standardavvikelsen är känd. I detta fall kan vi använda kvantiler för den standardiserade normalfördelningen, se tabellsamlingen. Vi bestämde därefter konfidensintervall för väntevärdet när standardavvikelsen är okänd och i detta fall kan vi använda kvantiler för t-fördelningen, se tabellsamlingen. Se även Figur 8 för exempel på täthetsfunktioner för t-fördelningar. Vi avslutade med konfidensintervall för standardavvikelsen av ett normalfördelat stickprov med okänt väntevärde och visade att vi då kunde använda kvantiler av chitvå-fördelningen, se tabellsamlingen. Se även Figur 9 för exempel på täthetsfunktioner för chitvå-fördelningar. En allmän metodik för att bestämma konfidensintervall finns här och den innehåller också de tre fall som togs upp på föreläsningen.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 9 (151127)Föreläsning 9 var första föreläsningen om statistikteori. Givet ett slumpmässigt stickprov med numeriska mätdata vill vi uppskatta en eller flera parametrar (exempelvis väntevärdet eller variansen) i den fördelning som stickprovet antas komma från. Vi introducerade begreppet punktskattning, som är en funktion av stickprovet som för varje stickprov ger ett värde på den okända parametern. Stickprovet x kan ses som ett utfall av en stokastisk variabel X och på samma sätt kan punktskattningen ses som ett utfall av en stickprovsvariabel (där vi sätter in X istället för x i funktionen som definierar punktskattningen). Vi definierade begreppen väntevärdesriktighet, konsistens och effektivitet för punktskattningar och visade att stickprovsmedelvärdet och stickprovsvariansen kan användas som punktskattningar av väntevärdet och variansen. Vi avslutade med att diskutera maximum likelihood-metoden som är en generell metod för att härleda punktskattningar. Läs själva om minsta kvadrat-metoden som är ett alternativ till maximum likelihood-metoden.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 8 (151123)Föreläsning 8 behandlade de tre diskreta fördelningarna binomialfördelningen, Poissonfördelningen och den hypergeometriska fördelningen. Vi började med att visa att Bin(n,p)-fördelade stokastiska variabler kan ses som en summa av n oberoende Be(p)-fördelade stokastiska variabler. Detta synsätt användes dels för att bestämma väntevärde och varians för binomialfördelade stokastiska variabler, dels för att kunna applicera centrala gränsvärdessatsen och visa att binomialfördelningen är asymptotiskt normalfördelad. Vi undersökte hur normalapproximationen av binomialfördelningen kan göras ännu bättre med så kallad halvkorrektion. Vi studerade därefter Poissonfördelningen som fås från binomialfördelningen om vi låter n gå mot oändligheten och p mot noll. Vi visade en additionssats för Poissonfördelade stokastiska variabler och visade att en normalapproximation är möjlig även för Poissonfördelade stokastiska variabler. Vi avslutade med att undersöka den hypergeometriska fördelningen och visade hur den uppkommer i urnmodeller med återläggning. Även hypergeometriskt fördelade stokastiska variabler kan skrivas som en summa av Bernoullifördelade stokastiska variabler som dock blir beroende i detta fall, eftersom dragningen sker med återläggning. Om antalet kulor i urnan är mycket stort är motsvarande hypergeometriskt fördelade stokastiska variabler approximativt binomialfördelade.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 7 (151120)Föreläsning 7 behandlade normalfördelningen. Vi undersökte först den standardiserade normalfördelningen och dess täthets- och fördelningsfunktioner samt visade hur fördelningsfunktioner och kvantiler kan bestämmas ur tabeller. Vi fortsatte sedan med allmänna normalfördelningar och visade hur dessa kan överföras till standardiserade normalfördelningar med hjälp av en linjär transformation (subtrahera väntevärdet och dividera med standardavvikelsen). Vi noterade sedan att linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade och att det aritmetiska medelvärdet av oberoende normalfördelade stokastiska variabler är normalfördelat. Som varning för att det krävs någon form av oberoende för att summor av normalfördelade stokastiska variabler skall bli normalfördelad ges följande motexempel. Vi avslutade med att diskutera centrala gränsvärdessatsen, som säger att även aritmetiska medelvärden av n oberoende, likafördelade (men inte nödvändigtvis normalfördelade) stokastiska variabler är approximativt normalfördelade för stora värden på n. Figur 7 visar en jämförelse mellan sannolikhetsfunktionen för det aritmetiska medelvärdet av n oberoende Po(1)-fördelade stokastiska variabler och täthetsfunktionen för motsvarande normalfördelning. För den intresserade: Ett bevis av centrala gränsvärdessatsen med hjälp av Laplacetransform (momentgenererande funktion) samt ett bevis med Fourier-transform (karakteristisk funktion).Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 6 (151118)Föreläsning 6 inleddes med funktioner av tvådimensionella stokastiska variabler. Vi definierade väntevärden av sådana funktioner och undersökte specialfallet med summan av två oberoende stokastiska variabler i detalj. Vi visade att väntevärdet är en linjär funktion, dvs att väntevärdet av en linjärkombination av stokastiska variabler är lika med en linjärkombination av väntevärdena av de stokastiska variablerna. Vi definierade kovariansen och korrelationskoefficienten som mått på det linjära beroende mellan två stokastiska variabler och visade att oberoende stokastiska variabler också är okorrelerade, dvs har kovarians noll. Vi härledde även en formel för variansen av en linjärkombination av stokastiska variabler och avslutade med stora talens lag som säger att det aritmetiska medelvärdet av summor av oberoende, likafördelade stokastiska variabler konvergerar mot väntevärdet (jfr relativa frekvensers stabilitet). Figur 6 visar hur sannolikhetsfunktionen för det aritmetiska medelvärdet av n oberoende Po(1)-fördelade stokastiska variabler närmar sig väntevärdet 1 när n går mot oändligheten. Vi bevisade stora talens lag med hjälp av Markovs olikhet.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 5 (151110)Föreläsning 5 inleddes med att vi bestämde fördelningen för strikt växande och strikt avtagande funktioner av kontinuerliga stokastiska variabler. Vi ägnade sedan återstoden av föreläsningen åt tvådimensionella stokastiska variabler. Vi definierade simultana fördelnings-, sannolikhets- och täthetsfunktioner samt visade hur de marginella fördelnings-, sannolikhets- och täthetsfunktionerna kan bestämmas genom summering eller integration. Figur 5 visar ett exempel på en simultan täthetsfunktion för tvådimensionell normalfördelning. Vi definierade oberoende stokastiska variabler och såg hur oberoende kan avgöras från fördelnings-, sannolikhets- och täthetsfunktionerna. Vi avslutade med en tillämpning av fördelningen för maximum och minimum av ett antal oberoende stokastiska variabler.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 4 (151110)Föreläsning 4 behandlade kontinuerliga stokastiska variabler, vilka kan anta alla värden i ett eller flera intervall på tallinjen. Vi kan tolka en kontinuerlig stokastisk variabel som att den totala sannolikhetsmassan är utspridd på tallinjen och fördelningen av sannolikhetsmassan bestäms av täthetsfunktionen. Sannolikheten att värdet på en kontinuerlig stokastisk variabel ligger i ett visst intervall fås genom att integrera täthetsfunktionen över intervallet i fråga. Vi definierade också fördelningsfunktionen, vilken kan användas för att beskriva både diskreta och kontinuerliga stokastiska variabler. Vi undersökte sambandet mellan fördelningfunktionen och sannolikhets- och täthetsfunktionerna och pratade om vad som menas med en kvantil. Vi definierade ett par viktiga kontinuerliga sannolikhetsfördelningar, såsom exponentialfördelningen och normalfördelningen, och diskuterade deras egenskaper och användningsområden. Figur 3 visar några exempel på exponentialfördelningar med parametervärden 0.5, 1 respektive 1.5 och Figur 4 visar några exempel på normalfördelningar med olika värden på parametrarna mu och sigma. Vi avslutade med att definiera väntevärde, varians och standardavvikelse för kontinuerliga stokastiska variabler.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 3 (151106)Föreläsning 3 behandlade diskreta stokastiska variabler, vilka kan anta ett ändligt eller uppräkneligt oändligt antal olika värden. Vi definierade sannolikhetsfunktionen, undersökte dess egenskaper och bestämde sannolikhetsfunktionerna för några vanligt förekommande diskreta sannolikhetsfördelningar, såsom likformiga fördelningen, Bernoullifördelningen, ffg-fördelningen, binomialfördelningen och Poissonfördelningen. Figur 1 visar några exempel på binomialfördelningar med n = 20 och p = 0.1, p = 0.25, p = 0.5 respektive p = 0.75. Vi visade hur Poissonfördelningen kan härledas som en approximation av binomialfördelningen. Figur 2 visar en jämförelse mellan Bin(20,0.1) och Po(2). Vi avslutade med av definiera väntevärde, varians och standardavvikelse för diskreta stokastiska variabler.Notera att ett litet fel smugit sig i föreläsningsanteckningarna under tillämpningen av ffg-fördelade stokastiska variabler. En ffg-fördelad stokastisk variabel kan beskriva antalet försök till och med det första lyckade försöket, inte antalet försök innan det första lyckade försöket. Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 2 (151104)Föreläsning 2 inleddes med två exempel på urnmodeller där dragning sker med respektive utan återläggning. Vi undersökte betingade sannolikheter, visade satsen om total sannolikhet samt Bayes sats för att "vända på en betingning". Exemplet om sjukdomsdiagnostik är hämtat från en artikel från Scientific American January 2012. Vi avslutade med oberoende händelser.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar Föreläsning 1 (151103)Föreläsning 1 innehöll introduktion till kursen samt en kort presentation av deskriptiv statistik. Vi definierade de grundläggande sannolikhetsteoretiska begreppen slumpförsök, utfall, utfallsrum och händelse med exempel på diskreta utfallsrum. Vi visade att händelser kan tolkas som mängder och att mängdlärans operationer komplement, union och snitt därmed är applicerbara. Vi gick igenom Kolmogorovs axiomsystem och några satser som följer ur detta samt diskuterade kopplingen mellan relativa frekvensen och sannolikheten för en händelse. Vi avslutade med den klassiska sannolikhetsdefinitionen som är användbar då utfallen kan anses vara lika sannolika.Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Jan Grandells och Timo Koskis föreläsningsanteckningar
|
 |
|
Sidansvarig: Tatjana Pavlenko Uppdaterad: 2013-07-27 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}